CoT Individual Report Script
在本次暑期课程中,在 Reading Paper 这一阶段,我们小组抽中了 Chain-of-Thought reasoning without prompting 这篇论文,在读完这篇论文之后,我对 Chain of Thought 产生了兴趣,所以我想在 Individual Report 中,对 Chain of Thought 的相关论文进行进一步的阅读,并对其进行总结。
What is Chain of thought?
Chain of Thought 是一种短句的序列,模拟了一个人在回答问题时可能会进行的推理过程。CoT Promoting 是一种方法,通过提供一系列提示,引导模型进行一系列的思考。 在我看来CoT Promoting 其实给模型回答问题提供了一种思考范式,就像我们在解题时思考问题的步骤,这里只是把思考问题的步骤交给模型,引导模型生成答案。
与 Zero Shot 相比CoT Promoting 有几个优点 首先是CoT提供了可解释性,当我们得到答案时,不仅仅得到答案,而且还能知道答案是怎么来的。 其次是CoT把复杂问题分解成简单的步骤,提高回答的准确性
Experiments on three large language models show that chain-of-thought prompting improves performance on a range of arithmetic, commonsense, and symbolic reasoning tasks.
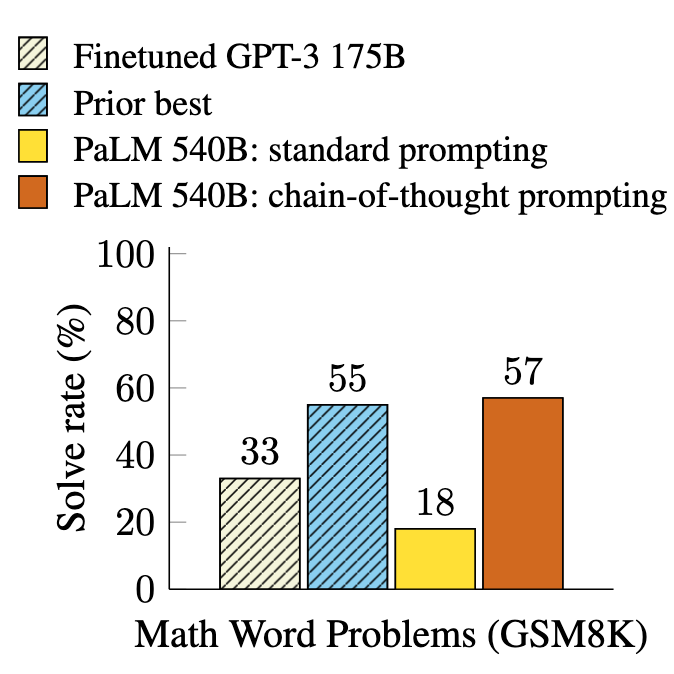
PaLM 540B uses chain-of-thought prompting to achieve new state of-the-art performance on the GSM8K benchmark of math word problems.
How to elicit Chain of thought
通过查阅相关文献,我认为大概可以分为两种方法 一种是通过Promoting的方式引导出 Chain of Thought,另一种是通过改变Decoding方法引导出 Chain of Thought。
Depend on Prompting
首先我们来看看如何通过Promoting的方式引导出 Chain of Thought, 通过查阅相关文献,我发现了几种方法, 在这里我主要介绍Auto-CoT 和 Active Prompting这两种方法
Auto CoT
CoT prompting can be categorized into two major paradigms. The first paradigm, known as Zero-Shot-CoT, adds a simple prompt like “Let’s think step by step” after the test question to facilitate the reasoning chains in LLMs. This approach does not require input-output demonstrations and is task-agnostic. The second paradigm, Manual-CoT, relies on manually designed demonstrations, where each demonstration consists of a question and a reasoning chain leading to the answer. Manual-CoT has shown superior performance but requires significant manual effort in designing task-specific demonstrations.

然而手动设计 CoT Prompting 需要大量的人力,而且不适用于所有的任务,因此,作者提出了 Acto CoT,这是一种自动设计 CoT Prompting 的方法。简单地说,Auto-CoT 有两个主要步骤:
- Partition questions of a given dataset into a eight clusters — sentence-BERT is used to encode the questions and then clusters are formed based on cosine similarity.
- Select a representative question from each cluster and generate its reasoning chain using Zero-Shot-CoT with simple heuristics — the heuristics involve not selecting a question with more than 60 tokens or a rational with more than five reasoning steps. The heuristics aim to improve the chance of the auto generated response being correct.
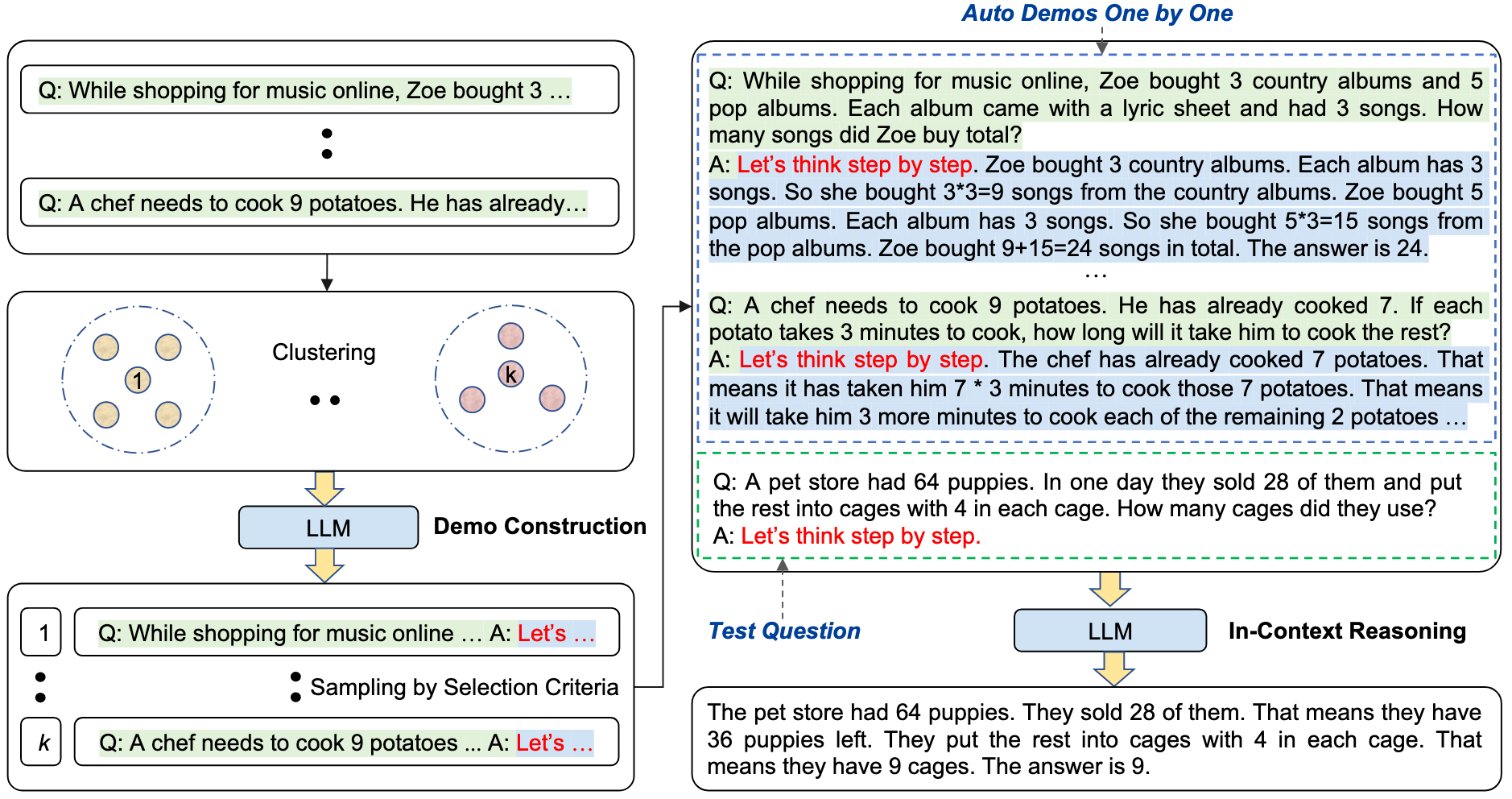
作者最先尝试的是采用Zero-Shot-CoT的方式生成一系列的推理说明信息,但发现这样的简单办法无法有效解决人工设计所带来的收益,因为Zero-Shot-CoT在推理链中会存在错误。
经过分析发现推理说明中问题的多样性对于缓解Zero-Shot-CoT引起的错误的影响是至关重要的。
- Let's think not just step by step but also one by one
Active Promoting
在这个方法中,主要研究了如何选取 CoT 的提示词. 简单的说,就像在考试时,找出我们觉得比较困惑的问题并先学习它们,而不是通过随机选择问题来学习,有助于取得更好的成绩。
作者使用了 4 个不确定性指标——分歧、熵、方差、自信 The authors have used disagreement and entropy for the main experiments.
然后,根据不确定性指标确定的前“n”个不确定问题将用于人工注释。
These ’n’ uncertain questions are annotated by human annotators to generate CoT rationale and then used as examples for few shot prompting along with the test question to generate response.
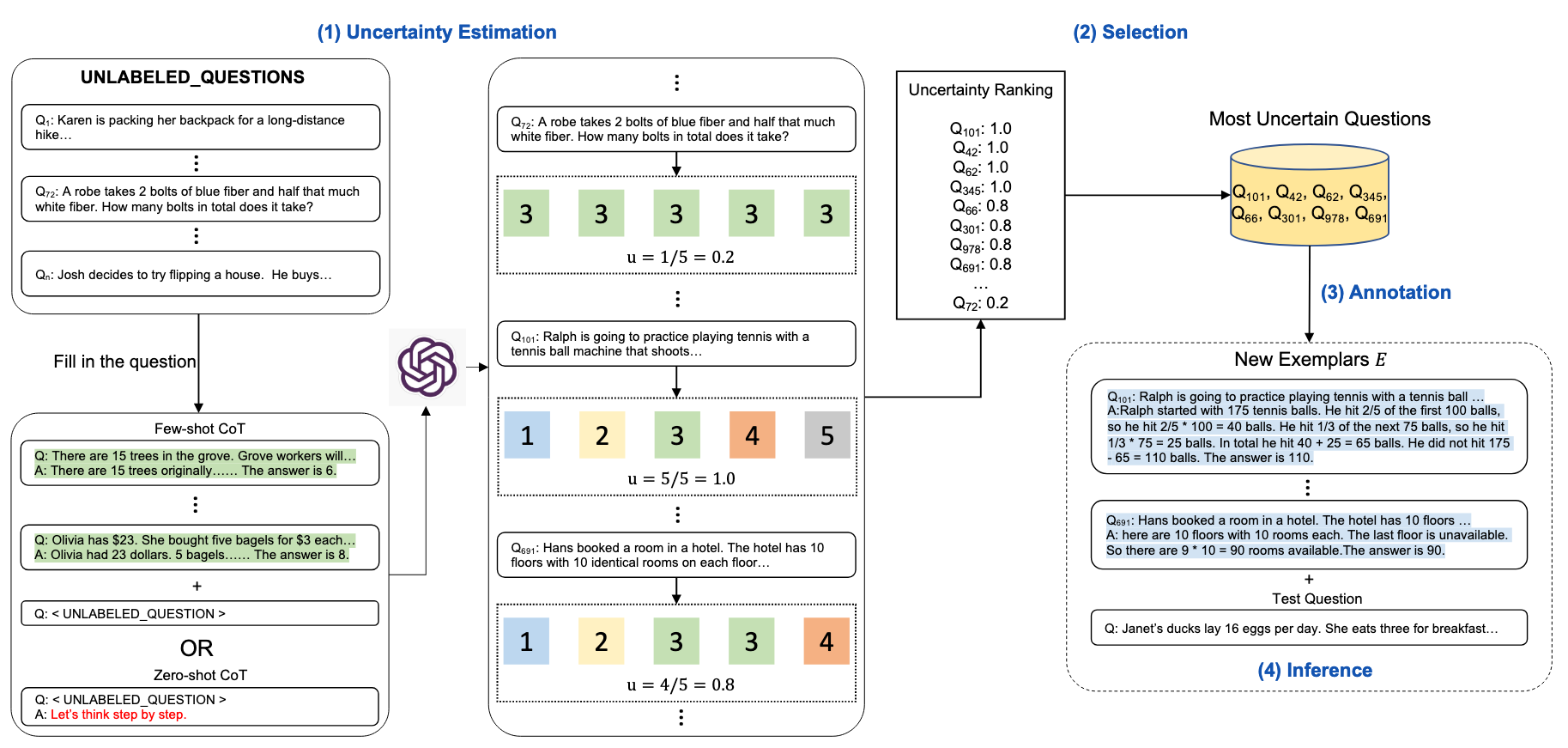
Auto-CoT 自动生成是基于多样性的,Active-CoT 是基于不确定性的, 从结果上看后者优于前者,原因在于人工标注和数据集的不确定性,如果数据集中有错误的标注,Auto-CoT 会受到影响,而 Active-CoT 会自动排除这些错误的标注,提高了模型的性能。
Depend on Decoding
传统的解码方法是贪心解码, 贪心解码是一种简单的序列生成方法,在这种方法中,每一步都选择具有最高概率的下一个词作为输出,直到生成结束符或达到预定的输出长度。
贪婪解码的优点是实现简单,速度快,因为它只需在每一步选择一个最高概率的词。然而,这种方法有一个明显的缺点,即它可能会错过全局最优的序列。由于每一步都只选择局部最优的词,贪婪解码可能会导致生成的文本质量较低,缺乏连贯性和多样性。
Self-Consistency Decoding 相当于对答案做了一次聚合, 选择出现频率最高的结果作为答案
CoT-Decoding 则是在 Self-Consistency的基础上引入了一个置信度的指标。 通过计算每条推理路径的置信度并对相同答案的推理路径进行聚合,最后选择置信度最高的路径作为最终的推理路径。在此处我认为这种置信度的计算类似做选择题时的排除法,我们在什么情况下排除选项,首先一定要满足的是选项是错误的,然后再从剩下的选项中选择最有可能的答案。而此时,往往选项之间的差距比较大。当选项之间差距不大的时候,难以决策,或者说决策的准确性会下降,对应到解码就是,不同 token 的概率差距不大的时候;当选项答案差距较大时,选择的信心会提升,对应到解码就是,不同 token 的概率差距较大的时候。CoT-Decoding 就是通过累积 被预测 token 中 top-2 token 的概率差值,来计算置信度。
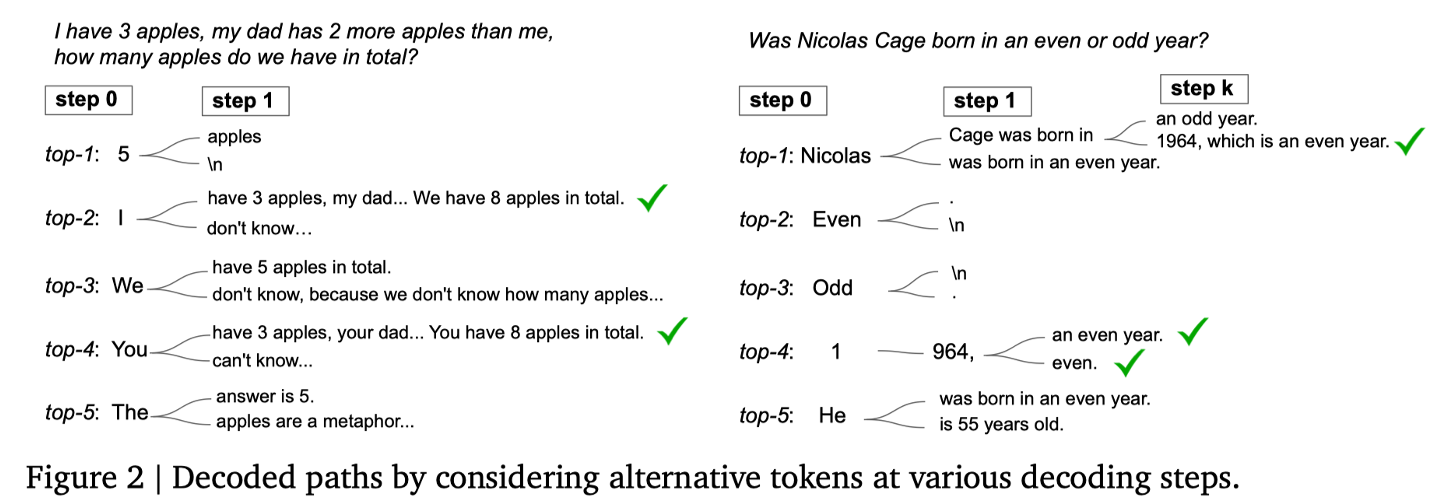
Chain-of-Thought 本质上是引到出模型内已经存在的正确的推理路径,而不是无中生有
Exploring Variants of Chain of Thought
Finally, I also came across two articles that caught my attention due to their names being similar to Chain of Thought. One is about Tree of Thought, and the other concerns Graph of Thought. I would like to share these concepts with you here as well.
Tree of Thought
这种方法在我看来,主要是用来解决寻找方案的问题,而不是解决答案的问题。正如文章提到的 Game-24 这个问题,我们知道答案一定是4个数相加等于24,在此基础上,Tree of thought,可以采用 DFS 或 BFS 的方式,来寻找解决方案。
Graph of Thought
Conclusion
This report has explored the Chain of Thought (CoT) approach, focusing on enhancing the reasoning capabilities of language models through diverse prompting and decoding strategies. Auto CoT and Active Prompting refine how models generate and improve answers by harnessing problem diversity and addressing uncertainty, respectively. Meanwhile, decoding techniques like Self-Consistency Decoding and CoT Decoding improve answer accuracy and confidence by emphasizing the most consistent and probable outcomes.
References
Diao, S., Wang, P., Lin, Y., Pan, R., Liu, X., & Zhang, T. (2024). Active Prompting with Chain-of-Thought for Large Language Models (No. arXiv:2302.12246). arXiv. https://doi.org/10.48550/arXiv.2302.12246
Kim, S., Joo, S. J., Kim, D., Jang, J., Ye, S., Shin, J., & Seo, M. (2023). The CoT Collection: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning (No. arXiv:2305.14045). arXiv. https://doi.org/10.48550/arXiv.2305.14045
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., & Zhou, D. (2023). Self-Consistency Improves Chain of Thought Reasoning in Language Models (No. arXiv:2203.11171). arXiv. https://doi.org/10.48550/arXiv.2203.11171
Wang, X., & Zhou, D. (2024). Chain-of-Thought Reasoning Without Prompting (No. arXiv:2402.10200). arXiv. https://doi.org/10.48550/arXiv.2402.10200
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2023). Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (No. arXiv:2201.11903). arXiv. https://doi.org/10.48550/arXiv.2201.11903
Zhang, Z., Zhang, A., Li, M., & Smola, A. (2022). Automatic Chain of Thought Prompting in Large Language Models (No. arXiv:2210.03493). arXiv. https://doi.org/10.48550/arXiv.2210.03493